未知のなかば
 道なき未知
道なき未知
第3回 ToMMoではこうやってDNAを解読しています(前編:次世代シークエンサー)
ヒトゲノムの解読、それはヒトの細胞の中のDNAに含まれる塩基配列情報を読み解く、ということです。
アデニン(A)、チミン(T)、グアニン(G)、シトシン(C)という4種類の塩基の並びを一つずつ調べていく、たったそれだけのことですが、そこには大変な困難があります。なにしろヒト一人のゲノムに含まれる塩基の数は60億個。塩基一つが1文字だとすると60億塩基の情報は新聞紙500万枚に相当します。そして塩基は非常に小さな物質で、なおかつ文字のように簡単に判別ができるわけではありません。新聞の文字を読むようにはいかないでしょう。さらにDNAは生体試料。移送や保存も特殊な方法が必要となります。これらの困難をなんとか克服したとしても、あまりにも時間がかかりすぎるようでは問題です。初めてヒト一人のゲノムを解読したとき、13年もの年月が費やされました。これは偉大な業績ではありますが、このスピードで解読していたら、ToMMoが目指している、たくさんの方々の遺伝情報が含まれるデータベースができるのは一体いつになるかわかりません。
科学者たちは、より正しく、より速くDNAを読むために、たくさんの試行錯誤を行ってきました。様々な方法が試みられ、うまくいく方法もあればそうでないのもあり、また一時主流だったにもかかわらず、いつの間にか時代遅れになってしまったものもあります。現在でもその方法はどんどん改善され、ほんの数年前には考えもしなかったような方法が日々試されています。
10年ほど前、革新的なDNAの解読装置が現れました。「次世代シークエンサー」です。この次世代シークエンサーによりDNAの解読スピードは劇的に速くなり、一度に大量のDNAを解読することが可能となりました。次世代シークエンサーの登場はゲノム研究にとって大きなターニングポイントとなったのです。
今回は私たちが使用している次世代シークエンサーを用いたDNAの解読方法をご紹介します。この方法は、現段階でヒトゲノム解読では非常に精度の高い方法とされ、多くの研究施設で採用されています。現在、存在する様々な手法の中で、東北メディカル・メガバンク事業に非常に適しています。
STEP1
まずはDNAを断片化します。断片化した大量のDNAを同時に処理することにより高速に解読することができます。

| 解説 |
断片の長短に関わらず、1本の断片のうち塩基を正確に解読できるのはごく一部、150塩基程度(ToMMoでは162塩基)です。このため、長いDNAのままでは読み残しがたくさん出てしまいます。DNAを切り刻んでたくさんの短い断片を作成したほうが、効率よく解読することができます。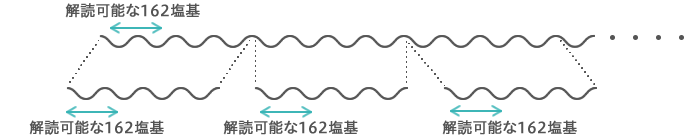 |
STEP2
二重らせんになっているDNAをほどき、一本鎖にします。調べやすいように、片端をガラス板に固定します。
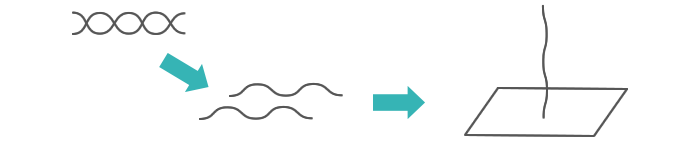
| 解説 |
DNAを構成している塩基は、AとT、GとC、のようにペアとなる組み合わせが決まっています。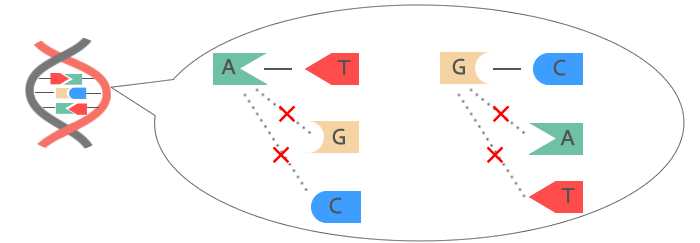 |
つまり、一本鎖があれば、もう一本の塩基の並びは判明します。この仕組みを利用して塩基の並びを解読することができます。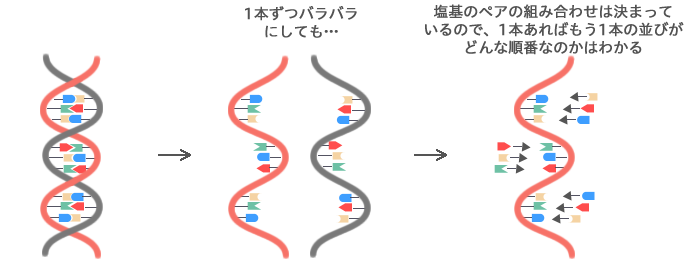 |
| 塩基の並びを解読するためには塩基のペアを順番に作らなければなりません。塩基のペアを順番に作るためには ・作りはじめのとっかかりとなる「プライマー」 ・塩基のペアをプライマーにつなげていく「酵素」 が必要になります。 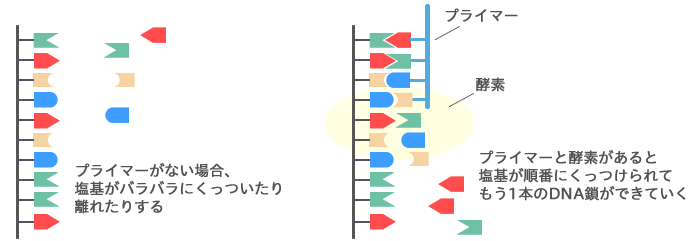 |
STEP3
DNAの断片にプライマーをくっつけます。プライマーにつながる次の塩基から解読をスタートします。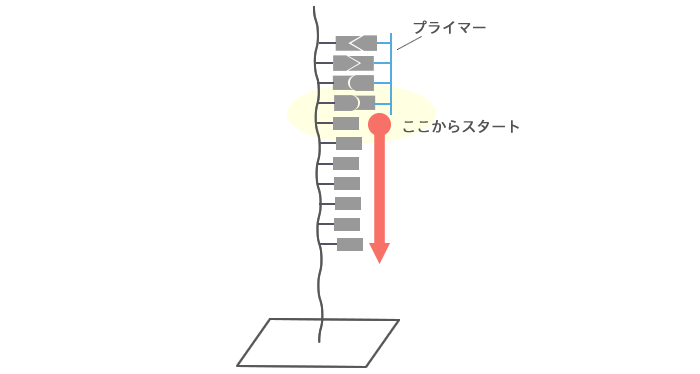
STEP4
蛍光色素が付いた塩基を流し込みます。まずはプライマーに続いて塩基が1つくっつきます。A,T,G,C それぞれ異なる色の蛍光色素が付いているため、その塩基が A,T,G,C のどれなのか判明します。たとえば赤色がくっついたならTとAのペアができたことがわかります。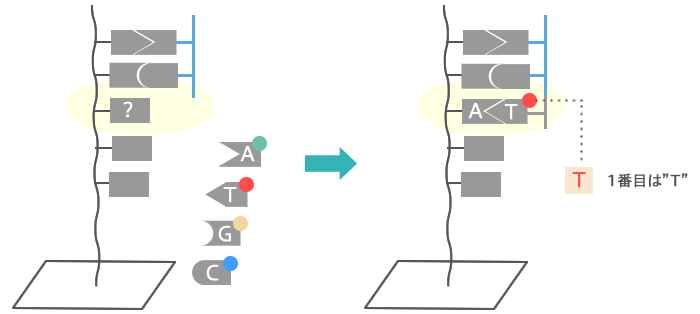
STEP5
STEP4で判明した塩基の次に再度塩基をくっつけ、同様に判定します。これを何回も繰り返して塩基の並びを順番に解読していきます。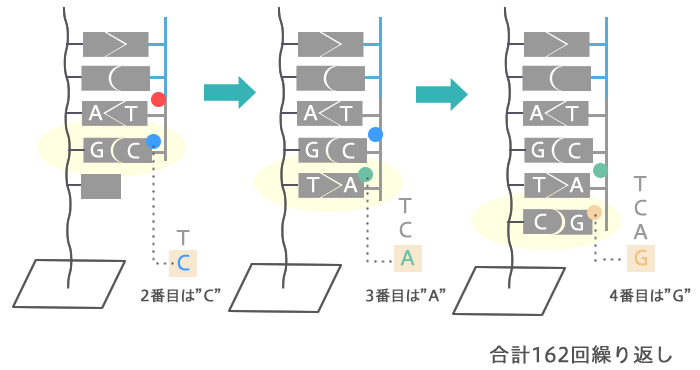
STEP6
一度に1本だけを調べるのではなく、STEP1で切り刻んだたくさんの断片を一気に調べます。数億本の断片を並行して一度に調べることができます。このようにしてヒト一人分のゲノムを解読します。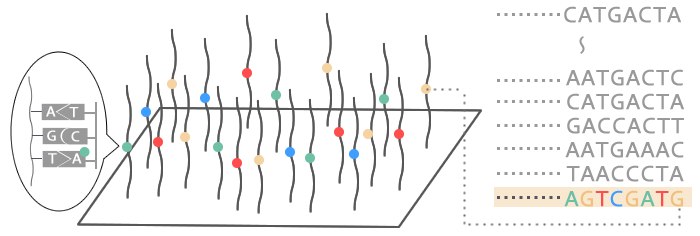
ここまでで判明するのは、たくさんの162塩基分の細切れの情報です。この段階ではこの情報が、もともとの長いDNAのどこの部分にあたるのか、わかりません。162個ずつバラバラになっているものを、60億個の並び、新聞で言えば500万枚の紙面の何ページ目のどこに相当するかあてはめていく……、途方もない作業であることがイメージできるでしょうか?
どうやってこの途方もない作業を行っているか、これについては、次回第4回 ToMMoではこうやってDNAを解読しています(後編:スーパーコンピュータ)でご紹介しましょう。
(担当:是枝幸枝)