未知のなかば
 道なき未知
道なき未知
第4回 ToMMoではこうやってDNAを解読しています(後編:スーパーコンピュータ)
前回は、次世代シークエンサーを用いたDNAの解読方法をご紹介しました。第3回 ToMMoではこうやってDNAを解読しています(前編:次世代シークエンサー)
次世代シークエンサーで判明するのは、DNAから塩基の並びを読み取るところまでです。「塩基の並びがわかったんだから、これでDNAは解読できたじゃないか」そう思われるかもしれません。ところが、次世代シークエンサーで解読し終わった時点では、162塩基分の細切れのデータが膨大にあるだけで、この情報が、ゲノムのどこの部分にあたるのかはわからないのです。162文字の文字列それぞれが、とてつもなく長い物語の第何巻の何ページ目にあたるのか?これを調べなければ物語を理解することはできません。ここで威力を発揮するのが「スーパーコンピュータ」です。
「スーパーコンピュータ」は、膨大な計算処理が可能な大規模コンピュータです。報道等でもよく取り上げられるように、気象など身近な事柄をはじめ、製品開発、金融など、様々な分野で利用されています。前回ご紹介した、次世代シークエンサーを用いたDNA解析では、塩基の並びを読み取った後に膨大な計算処理が必要となるため、「スーパーコンピュータ」のような高性能なコンピュータの存在が前提となります。「次世代シークエンサー」と「スーパーコンピュータ」、この二つの組み合わせにより、DNAの大量解読が可能となったのです。
今回は、「スーパーコンピュータ」が、どのようにして次世代シークエンサーが読み取ったデータをヒトのゲノム配列情報に再構成していくかをご紹介しましょう。
STEP1
次世代シークエンサーでDNAを解読した結果、162塩基分の情報がたくさんできました。しかし、この段階ではこの情報が、もともとの長いDNAのどこの部分にあたるのか、つまりどういう順番に並び替えればよいのか、わからない状態です。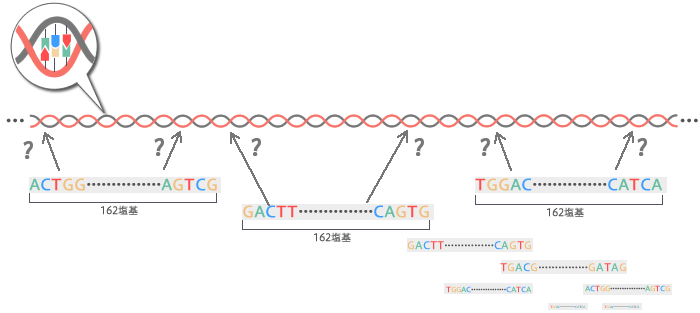
| 解説 |
| 「国際参照ゲノム配列」という、2003年までに膨大な時間とコストをかけて解読した、全ゲノム配列のいわば手本があります。ヒトのゲノム配列の個人差は、0.1%程度と言われています。つまり大部分の箇所で一致するのです。この手本をガイドにすれば、細切れの情報が、ヒトのゲノム配列のどこに相当するのか大体わかるのです。 なお、「国際参照ゲノム配列」は複数の欧米人のDNAをもとにして作成されています。  |
STEP2
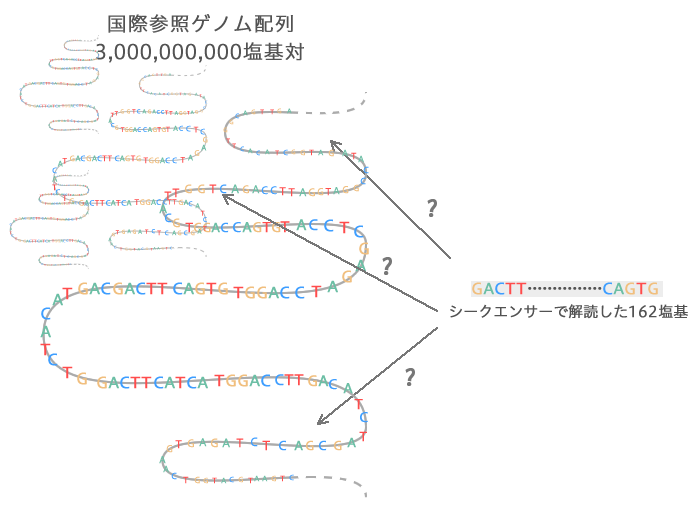
国際参照ゲノム配列にあてはめて、どれがどの部分にあたるか予想します。膨大なピース数のパズルを解くようなものです。
 STEP3
STEP3
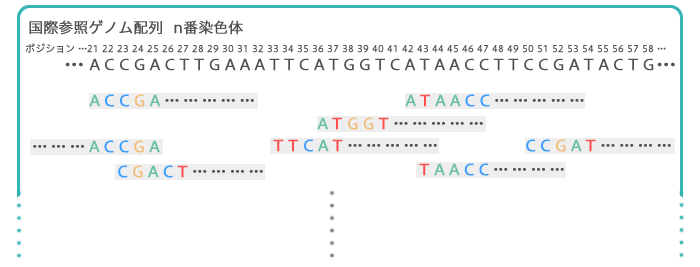
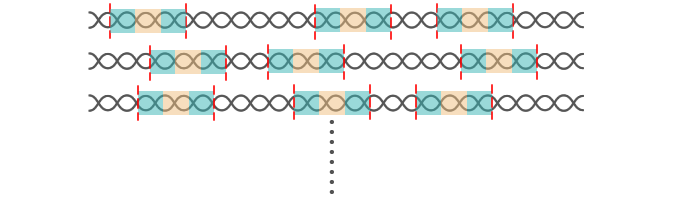
たくさんあるDNA情報の断片を、それぞれ当てはめていって、可能な限り埋めていきます。場所によっては重複するところもありますが、一致する箇所にどんどん重ねていきます。
| 解説 |
| なぜ、ここでDNA情報の断片が何重にも重なっているのか、不思議に感じる人もいるかもしれません。「前編:次世代シークエンサー」でご紹介したように、読み込んだ次世代シークエンサーで解読できる塩基は、DNAの断片のうちごく一部、150塩基程度(ToMMoでは162塩基)です。
ToMMoでは、二本鎖のそれぞれについて、端から162塩基ずつ解読します。塩基はペアになる組み合わせが決まっているので、片方を解読すればもう片方の塩基の並びも判明します。これにより、DNAの断片の両端が解読可能となります。
このDNAの断片を作るとき、1組だけではなく何組もの同じDNAについて、ランダムに断片化します。つまりDNAの断片は、かなりの部分で重複しているのです。
解読できた部分をすきまなく埋まるように並べ替えていくと、すべての塩基の並びが判明します。
|


STEP4
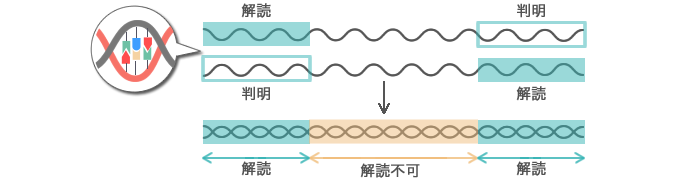
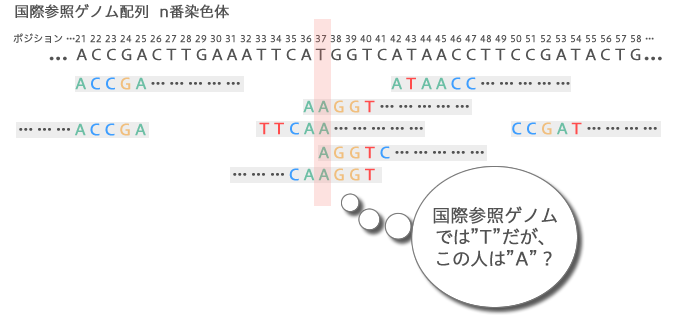
次々に当てはめていくと、国際参照ゲノム配列と合わない場所が出てきます。これが髪の色や背の高さなど一人ひとりの違いにつながります。場合によっては病気の原因となります。ゲノム配列の個人差は、0.1%程度と言われていますが、それでも300万箇所にもなります。この個人差を考慮しながら場所を確定していかなければなりません。
STEP5
すべて当てはめると、やっとひとり分の塩基配列が判明します。

いかがでしょうか?たとえるならば、数百万枚の新聞を一度シュレッダーにかけて、切れ切れの紙に書いてある162文字をばらばらに読み、さらにそれをつなぎ合わせて紙面データに戻し、やっとどんな記事が書いてあるかわかる、というところでしょうか?これがToMMoで行っているDNAの解読方法です。ここには書ききれませんでしたが、他にも様々な手順が必要となります。このようにしてヒトのゲノム配列を「端から端まですべて読み解く」ことができるのです。この方法を用いて、私たちは2013年11月に1000人の全ゲノムを解読することに成功しました。疾病原因探索の基盤となる 1000 人分の 全ゲノム配列の高精度解読を完了 ~1500 万個におよぶ新たな遺伝子多型を収集~【プレスリリース】
また広く研究に役立てていただけるよう2014年8月に、この解析結果の一部を公開しました。東北メディカル・メガバンク計画「全ゲノムリファレンスパネル」情報の部分的な一般公開を開始【プレスリリース】
犯罪捜査、親子の判定、いろいろなところでDNAは利用されていますが、ひとつひとつの塩基をすべて調べるのではなく、ゲノムの中の何か所かを部分的に調べる場合が多いようです。この解析方法は比較的容易に実施でき、コストもそれほどかかりません。
なぜ私たちToMMoは大変な労力をかけて「端から端まですべて読み解く」のでしょうか?それはゲノムのまだ解らない機能や役割、その中でも特に病気の原因や治療法を明らかにするためです。病気の原因にもなりうる一人ひとりの違いは、ゲノムの様々な場所に存在します。様々な場所に散らばる違いを明らかにするためには、端から端まですべてを正確に、そしてできるだけ多くの方のDNAを読むということが必要になります。さらにその膨大な情報のどこがどう違っているのか、ひとつひとつ比較して、その違いがどう病気と関わるのか調べる。この地道にも見える仕事に私たちは日々取り組んでいるのです。
(担当:是枝幸枝)