ゲノムの時代へ
膨大な情報を、
わたしたちは自在にあやつって、
新しい時代を拓くことができるのか、
やがてくる明日への羅針盤に
ヒトだけが違う?!
言語を司る遺伝子
図を拡大
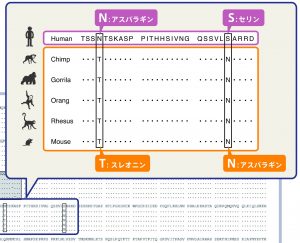 人間の言語能力は明らかに他の動物と比して卓越しています。しかし、どの遺伝子がヒトに特異的な言語の進化を司っているのかは、結論はまだ出ていません。遺伝学的に失語や構音障害が発生する家系の解析から言語を司る遺伝子として注目を集めたのが転写因子として働くFOXP2(forkhead box P2)です。この遺伝子は言語機能や口腔運動機能障害を示す常染色体優性遺伝の遺伝病家系から同定されました。同遺伝子の変異アレルを継承した個人は、健常人と比べ低IQなど他にも様々な神経学的異常を示すのですが、言語機能の低下、言語を司る脳の領域の機能変化、口腔の機能異常などが目立つため「言語遺伝子」と呼ばれています。同遺伝子にはチンパンジーやネズミ等の動物とは異なり、ヒトにだけ特徴的な変化として、2箇所のアミノ酸置換があり、面白いことにこの2つの置換はネアンデルタール人ゲノムでも検出されました。こちらも現代人ゲノムの混入や、ネアンデルタール人と現生人類の過去の混血の結果だとか様々な議論があります。現在ではFOXP2の発現制御機構がヒトで特徴的な進化を遂げた可能性について検討されています。また、同遺伝子以外にもモノマネをする鳥などとの進化学的比較からKIAA0319など複数の遺伝子の進化がヒトの言語機能に関連する可能性も示唆されています。
人間の言語能力は明らかに他の動物と比して卓越しています。しかし、どの遺伝子がヒトに特異的な言語の進化を司っているのかは、結論はまだ出ていません。遺伝学的に失語や構音障害が発生する家系の解析から言語を司る遺伝子として注目を集めたのが転写因子として働くFOXP2(forkhead box P2)です。この遺伝子は言語機能や口腔運動機能障害を示す常染色体優性遺伝の遺伝病家系から同定されました。同遺伝子の変異アレルを継承した個人は、健常人と比べ低IQなど他にも様々な神経学的異常を示すのですが、言語機能の低下、言語を司る脳の領域の機能変化、口腔の機能異常などが目立つため「言語遺伝子」と呼ばれています。同遺伝子にはチンパンジーやネズミ等の動物とは異なり、ヒトにだけ特徴的な変化として、2箇所のアミノ酸置換があり、面白いことにこの2つの置換はネアンデルタール人ゲノムでも検出されました。こちらも現代人ゲノムの混入や、ネアンデルタール人と現生人類の過去の混血の結果だとか様々な議論があります。現在ではFOXP2の発現制御機構がヒトで特徴的な進化を遂げた可能性について検討されています。また、同遺伝子以外にもモノマネをする鳥などとの進化学的比較からKIAA0319など複数の遺伝子の進化がヒトの言語機能に関連する可能性も示唆されています。
参考文献:WIREs Cogn Sci 2013, 4:547-560. doi: 10.1002/wcs.1247
Scientific Reports | 6:22157 | DOI: 10.1038/srep22157
長く、直に読む技術へ シークエンサーの進歩
図を拡大
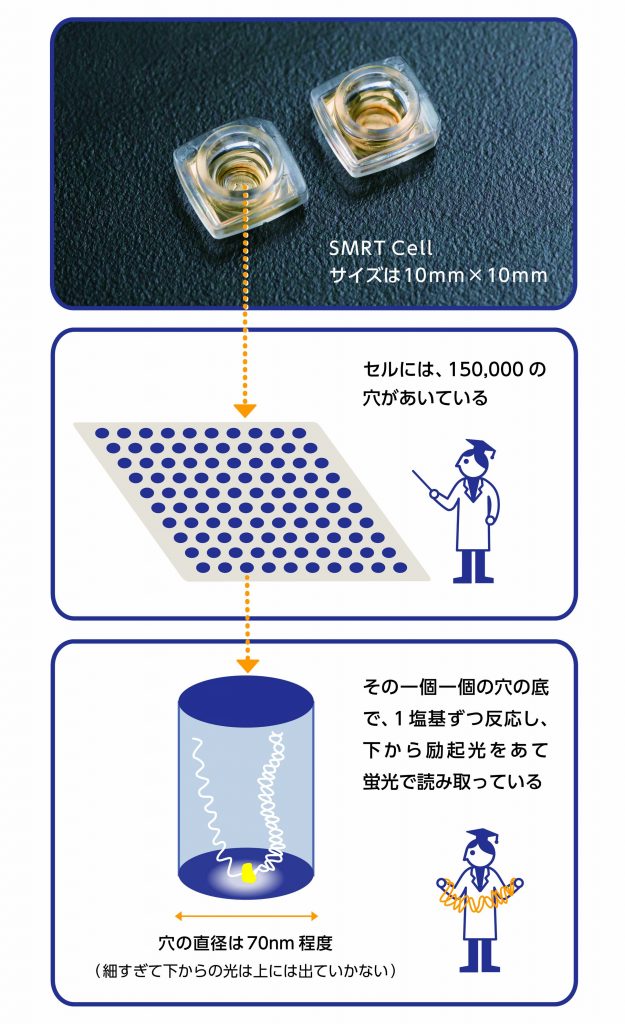 DNAの配列を解読する技術は、ここ十数年の間に驚異的な進歩を遂げました。昔は、サンガーシークエンス※1という方法で、DNAの断片を1本1本調べていましたが、次世代シークエンサーの登場により、数億から数十億本のDNA断片を一度に調べることが可能となりました。これにより、一昔前はヒト一人分のDNA配列を調べるのに10年以上かかりましたが、今はおよそ2日間で終わります。
DNAの配列を解読する技術は、ここ十数年の間に驚異的な進歩を遂げました。昔は、サンガーシークエンス※1という方法で、DNAの断片を1本1本調べていましたが、次世代シークエンサーの登場により、数億から数十億本のDNA断片を一度に調べることが可能となりました。これにより、一昔前はヒト一人分のDNA配列を調べるのに10年以上かかりましたが、今はおよそ2日間で終わります。
現在、主流の次世代シークエンサーは、蛍光色素を用いてDNA配列を解読しています。しかし、蛍光色素の検出感度が低いため、解析するDNA断片を増幅※2しなくてはならず、増幅しにくい部分の解析ができません。また、連続して200文字 (塩基) 程度しか読みとることができないため※3、ヒトゲノムで同じような配列が繰り返された場所などは、解読が困難です。
そんな中、全く異なる原理の「一分子長鎖シークエンサー」が注目されています。このシークエンサーも、蛍光色素を用いてDNA配列を解読しますが、検出感度が高いため、1分子 (1本) のDNAをそのまま、増幅することなく解析できます。また、連続して1万塩基以上読みとることができます。ただし、この一分子長鎖シークエンサー、まだ解析コストと解析にかかる時間の点で、多くの方のゲノムDNAを解読するのには適していません。しかし、ヒトゲノムの複雑な領域の解析に大きな威力を発揮するため、今後のさらに活用されていくものと思われます。最近では、蛍光色素を使わないで、直にDNA配列を解読する一分子長鎖シークエンサーも登場しました。蛍光の検出器がいらないため、シークエンサーを驚くほど小型化できるようです※4。今後も、「より長く、正確に、短時間で」DNA配列の解読技術は、更なる発展を遂げていくことでしょう。
{kind=link}
【参考】
※1 サンガーシークエンス: フレデリック・サンガー博士が発明したDNA塩基の決定方法で、ジデオキシ法とも呼ばれる。サンガー博士はこの発明で1980年にノーベル化学賞を受賞しています。
※2 増幅: ポリメラーゼ連鎖反応 (PCR)と呼ぶ方法で行います。1本のDNAからその複製を作り、さらにその複製を作り、この反応を繰り返し、1000本程度に増やします。
※3 1000本に増やしたDNAが二人三脚ならぬ、千人千一脚をしていると想像してください。走り始めは、みんな息も揃っていますが、そのうち、早く走る人、遅く走る人とバラバラになって、しまいには走れなくなりますよね。それと同じイメージです。丁度200歩ぐらいで、反応がバラバラになってしまうのです。
※4 最近試験的に売りだされた次世代シークエンサーは、USBのメモリスティック程度の大きさで、実際にパソコンのUSBに挿して使用するものもあります。
【関連リンク】
日本人の基準ゲノム配列(JRG)を公開
その遺伝子、ない方がマシ?
図を拡大
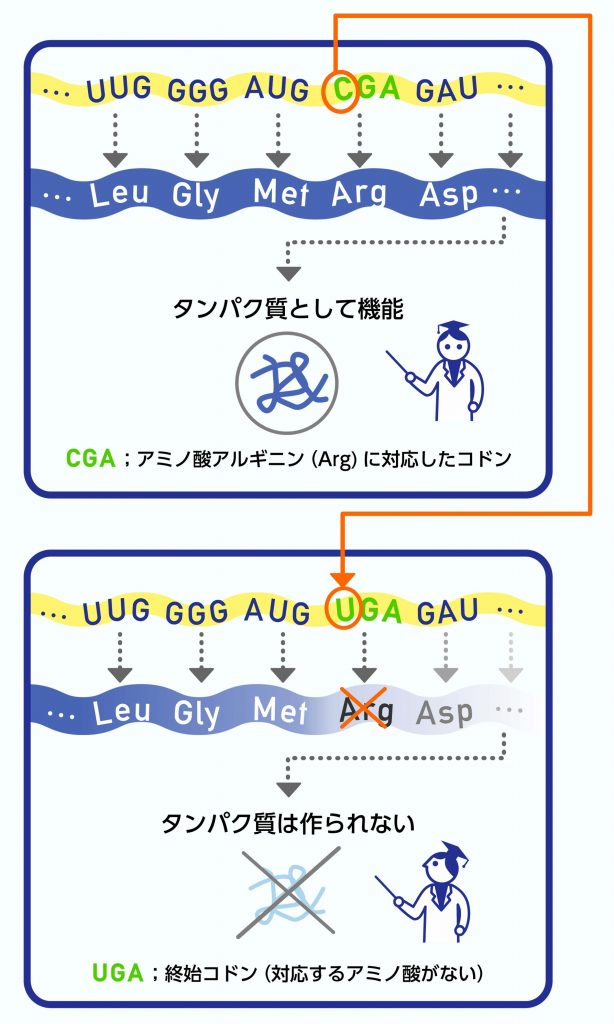 遺伝子の塩基配列のタンパク質をコードする部分の途中に予期せぬ終止コドンが入ってしまうと、遺伝子産物に重大な影響があります。実際、疾患の原因として知られているバリアントの中には、終止コドンを生じさせるものが沢山含まれています。しかし、ゲノム中の終止コドンを生じさせるバリアントは、疾患などの重大な効果を持つものばかりではありません。
遺伝子の塩基配列のタンパク質をコードする部分の途中に予期せぬ終止コドンが入ってしまうと、遺伝子産物に重大な影響があります。実際、疾患の原因として知られているバリアントの中には、終止コドンを生じさせるものが沢山含まれています。しかし、ゲノム中の終止コドンを生じさせるバリアントは、疾患などの重大な効果を持つものばかりではありません。
ヒトの遺伝子セットの中には、「多重遺伝子族」といって、起源を同じくしてメンバーの間ではアミノ酸配列が似通っている遺伝子族があります。なので、多重遺伝子族においては、一つの遺伝子が機能しなくても、同じ遺伝子族の他のメンバーが機能を補ってくれる場合もありますし、機能が多様化している場合もあります。
カスペース12という遺伝子は、ヒトでは11番染色体にありますが、じつは大部分の人はこの遺伝子の活性型を持たないのです。アフリカの人々の間では、タンパク質の全長が作られる活性型と、途中で終止コドンが入ることよる不活性型が共存します。一方でアフリカ以外に住む人々では、ほぼ不活性型ばかりです。カスペース12については、活性型を持つことによって、細菌の毒素への対応能力が低下することが示されていまして、敗血症の罹りやすさを高めたではないかと考えられています。カスペース12の不活性型が広まったのは、敗血症に抵抗性があったのではないか、と推測されています。
ヒトの遺伝子セットの中には、無くても大丈夫な遺伝子があります。ときには無い方が生き延びるのに有利なこともある、という考えが提唱されています。この仮説は、less is more(ない方がマシ) 仮説という、興味深い名前が付いています。進化の過程で、生物が持つ遺伝子の数は少々増えたり減ったりしています。ゲノム上に遺伝子が存在しても、不活性型のバリアントも持つ人もいるので、ほんとうに機能している遺伝子のセットには個人差が少々あります。多重遺伝子族は、生物進化における新しい機能の獲得において重要です。一方で、機能が多様化したためか、場合によっては有難くない働きをしてしまうこともあるようですね。
■カスペース(カスパーゼともいう)ファミリーとは?
システインプロテアーゼの一種で、標的となるタンパク質のアスパラギン残基のうしろを切断するので、Cystein-ASPartic-acid-proteASEを略して、caspase(カスペース)と名付けられました。他のカスパーゼを標的として、特定のアミノ酸の並びを認識して切断して活性化させ、連鎖的な増幅によって機能します。カスペースのメンバーの多くは、細胞死の誘導に関与していますが、中には炎症の誘導や免疫系の調節に関係するものもあります。
参考文献:
Olson MV. Am J Hum Genet. 1999 Jan;64(1):
Saleh et al. Nature.2004 429, 75-79
Xue Y et al.,Am J Hum Genet. 2006 Apr;78(4):659-70
遺伝子の発現のスイッチをONにする転写因子
図を拡大
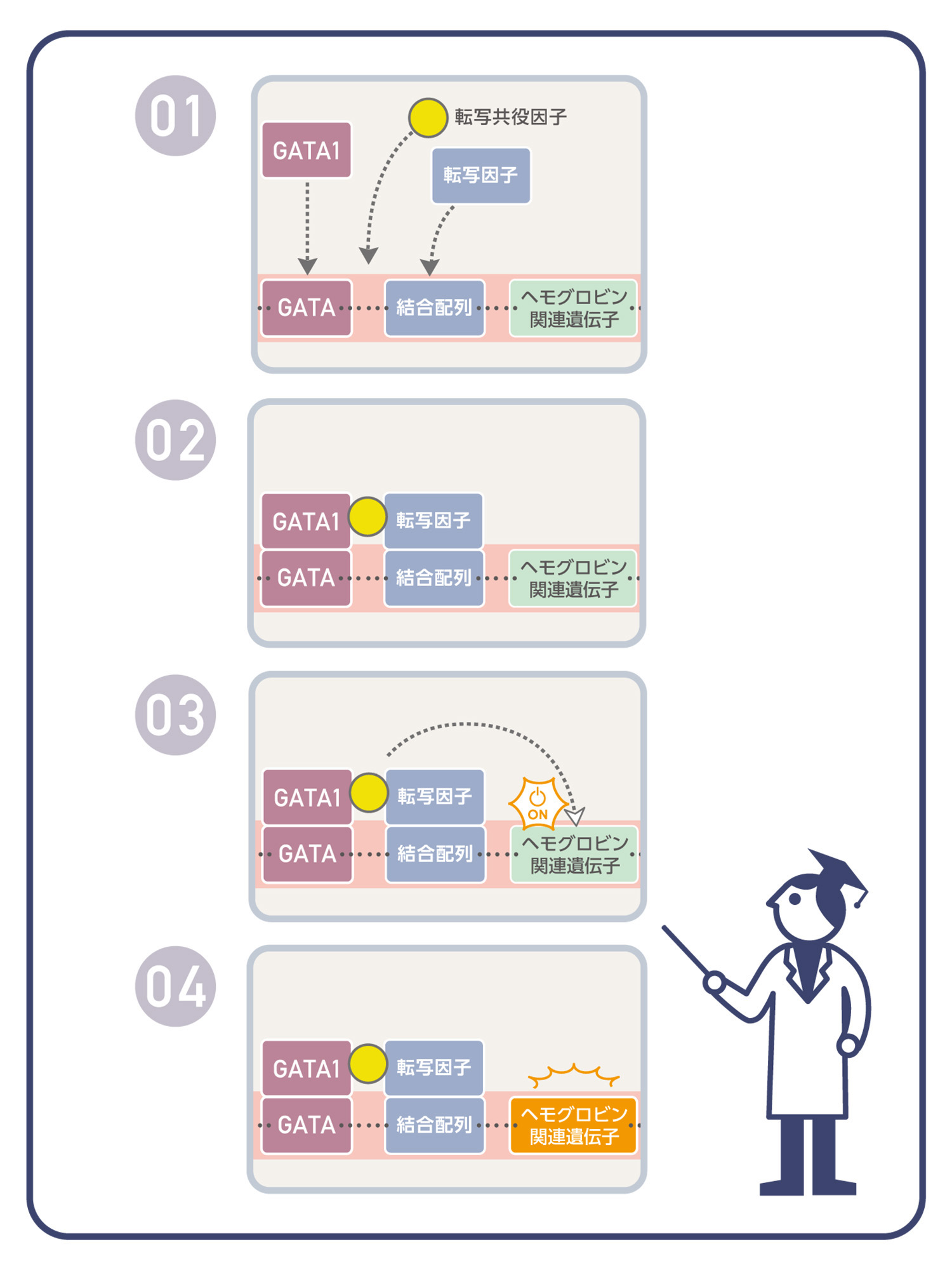
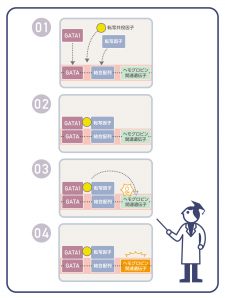 ヒトゲノムは、1セットあたり4種類の文字(A, T, G, C)を使って書かれた、約30億文字の言わば暗号配列です。しかし、タンパク質の設計図が書かれている部分は、暗号全体の数%です。それでは、残りの配列は何をしているのでしょうか。残りの配列の一部には、タンパク質が、どの細胞でいつ・どのくらい発現するか、厳密にコントロールするための配列(制御配列)が含まれています。私達の細胞は、基本的にどの細胞でも、つまり血液の細胞でも、皮膚になる細胞でも、同じゲノムを持っています。しかし、血液の基となる細胞が、血液の細胞になれたのは、血液で必要なタンパク質だけが、必要な時期に必要な量、発現したからです。例えば、血液で重要な遺伝子の近くにはG-A-T-Aという制御配列があり、血液で働くGATA-1と呼ばれる転写因子が認識して結合します。酸素を運搬するヘモグロビンをつくるのに必要な遺伝子の近くにも、-G-A-T-A-という配列があり、GATA-1転写因子が結合して遺伝子の発現をONにしています。しかし、G-A-T-Aという配列があれば、必ずそこにGATA-1が結合して、近くの遺伝子のスイッチをONにするのかというと、そうではありません。-G-A-T-A-の配列の周辺の配列や、協力して働く別の転写因子の結合する配列があるかなどの様々な条件が整って、初めてGATA-1が機能を発揮できるようになっています。さらに最近では複数の転写因子が結合したときに、その間をつなぐような働きをする転写共役因子の重要性も指摘されるようになってきました。制御配列も含めて、私たちのゲノムの多くの部分の機能は、分かっていません。ヒトの遺伝子の解読技術が飛躍的に進んだ現在、この制御配列の解明が期待されています。
ヒトゲノムは、1セットあたり4種類の文字(A, T, G, C)を使って書かれた、約30億文字の言わば暗号配列です。しかし、タンパク質の設計図が書かれている部分は、暗号全体の数%です。それでは、残りの配列は何をしているのでしょうか。残りの配列の一部には、タンパク質が、どの細胞でいつ・どのくらい発現するか、厳密にコントロールするための配列(制御配列)が含まれています。私達の細胞は、基本的にどの細胞でも、つまり血液の細胞でも、皮膚になる細胞でも、同じゲノムを持っています。しかし、血液の基となる細胞が、血液の細胞になれたのは、血液で必要なタンパク質だけが、必要な時期に必要な量、発現したからです。例えば、血液で重要な遺伝子の近くにはG-A-T-Aという制御配列があり、血液で働くGATA-1と呼ばれる転写因子が認識して結合します。酸素を運搬するヘモグロビンをつくるのに必要な遺伝子の近くにも、-G-A-T-A-という配列があり、GATA-1転写因子が結合して遺伝子の発現をONにしています。しかし、G-A-T-Aという配列があれば、必ずそこにGATA-1が結合して、近くの遺伝子のスイッチをONにするのかというと、そうではありません。-G-A-T-A-の配列の周辺の配列や、協力して働く別の転写因子の結合する配列があるかなどの様々な条件が整って、初めてGATA-1が機能を発揮できるようになっています。さらに最近では複数の転写因子が結合したときに、その間をつなぐような働きをする転写共役因子の重要性も指摘されるようになってきました。制御配列も含めて、私たちのゲノムの多くの部分の機能は、分かっていません。ヒトの遺伝子の解読技術が飛躍的に進んだ現在、この制御配列の解明が期待されています。
{kind=link}
治療の難しさはここにもあった?!
がん細胞ごとの遺伝子の違いと、シングルセル解析
図を拡大
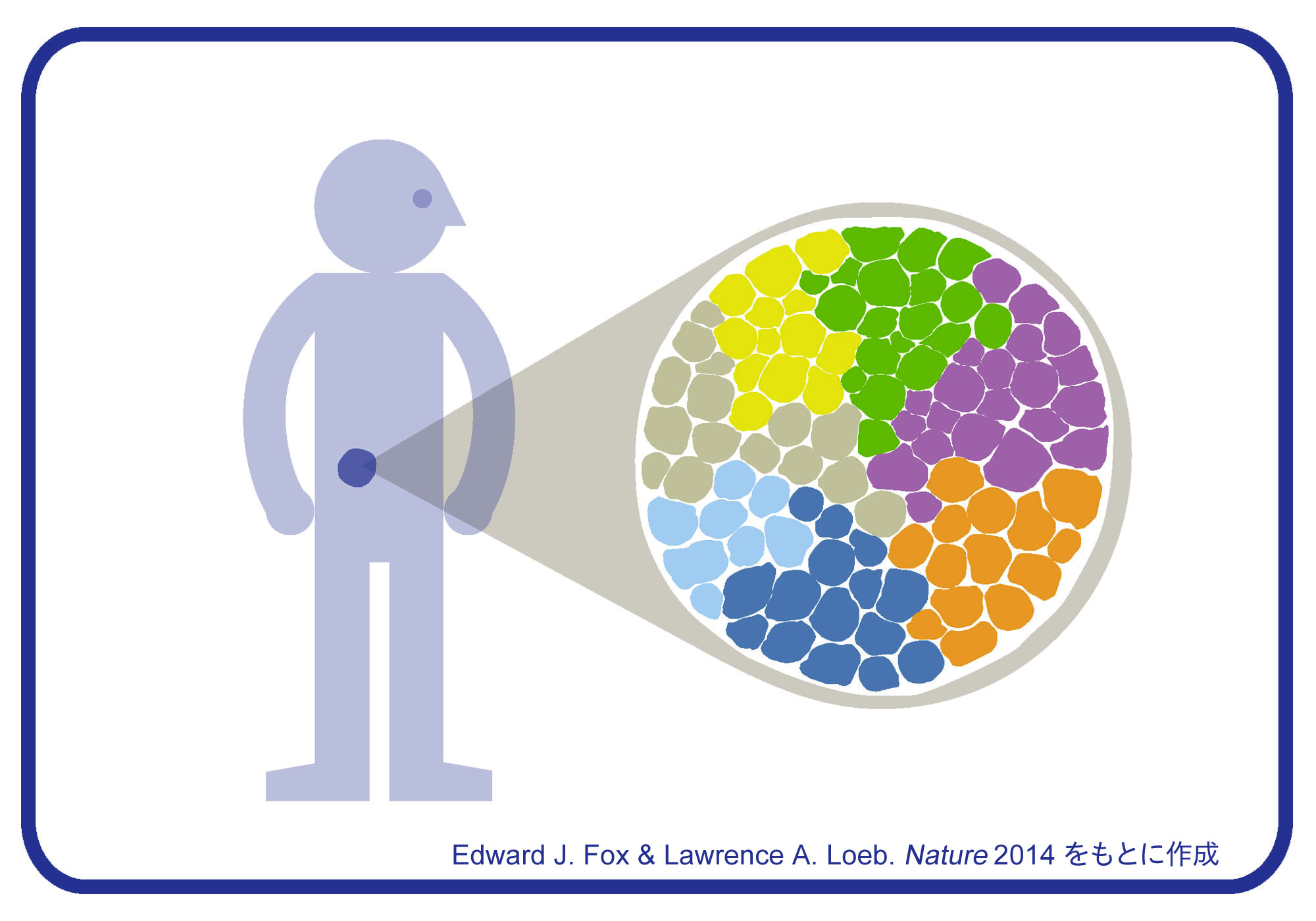 腫瘍を構成するがん細胞は、均一な遺伝情報をもつ集団ではなく、遺伝子に様々な違い(変異)があることが知られています。遺伝子の違いによって細胞の性質に違いが生まれるため、ひとつの腫瘍の中には増殖速度や薬に対する抵抗性の異なるさまざまながん細胞があり、こうした多様性が治療を難しくしている要因のひとつと考えられてきました。最近の研究では、腫瘍から取り出したがん細胞を一個ずつ解析し、腫瘍を個性のある細胞の集団として理解する試みが注目されています。2014年8月に米MDアンダーソンがんセンターから報告された論文では、予後の異なる2種類の乳がん(エストロゲン受容体陽性乳がん、トリプルネガティブ乳がん)からがん細胞の核を分取してゲノム解析を行い、2つの細胞集団における変異の分布や変異率の違い、がん細胞のクローン進化モデルなどが示されました。人が一人ひとり違うように、がん細胞にも多様性があることに目を向けることで新しい治療法が生まれるかもしれません。
腫瘍を構成するがん細胞は、均一な遺伝情報をもつ集団ではなく、遺伝子に様々な違い(変異)があることが知られています。遺伝子の違いによって細胞の性質に違いが生まれるため、ひとつの腫瘍の中には増殖速度や薬に対する抵抗性の異なるさまざまながん細胞があり、こうした多様性が治療を難しくしている要因のひとつと考えられてきました。最近の研究では、腫瘍から取り出したがん細胞を一個ずつ解析し、腫瘍を個性のある細胞の集団として理解する試みが注目されています。2014年8月に米MDアンダーソンがんセンターから報告された論文では、予後の異なる2種類の乳がん(エストロゲン受容体陽性乳がん、トリプルネガティブ乳がん)からがん細胞の核を分取してゲノム解析を行い、2つの細胞集団における変異の分布や変異率の違い、がん細胞のクローン進化モデルなどが示されました。人が一人ひとり違うように、がん細胞にも多様性があることに目を向けることで新しい治療法が生まれるかもしれません。
参考文献:Wang Y et al., Nature. 2014. Aug.
最新記事一覧
-
- きこえと遺伝子医療の現在
- 2025.12.26|宇佐美真一
-
- 人体を取りまく常在菌〜機能を知って共存しよう〜
- 2020.12.16|後藤まき
-
- なぜウイルスははやく変化するのか?
- 2020.09.08|山口由美
-
- 棒状で増やすか環状で増やすか―新たなシークエンサー開発―
- 2020.07.16|川嶋順子
-
- 新型コロナウイルスに対する抗体
- 2020.05.18|峯岸直子