jMorp Update and User Interface Changes (September 2022)
Tohoku Medical Megabank Organization (ToMMo) performed an update of the database, Japanese Multi Omics Reference Panel "jMorp", on September 29th, 2022. This time, we updated genome variation section, metabolome section, and metagenome section. We have also made significant changes to the user interface. See below for details.
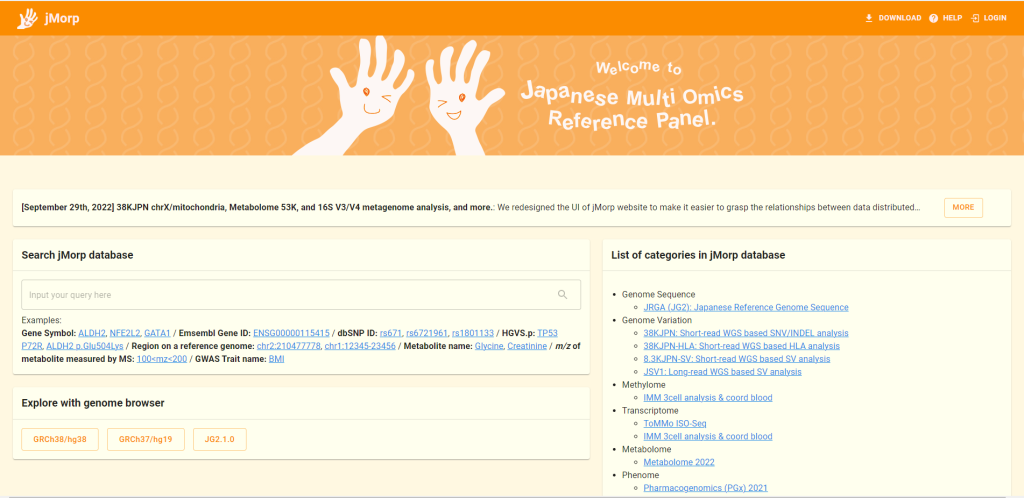
New user interface
Update Details
Genome Variation
We released 38KJPN chrX/mitochondrial allele/genotype frequency panel. Users can query 38KJPN dataset from search box located at the top page of jMorp.
Metabolome
We extended the number of samples for the following metabolome analysis: (1) up to approximately 53,000 volunteers (40,529 non pregnant and 12,594 (14,427 samples) pregnant ) for NMR analysis (45 metabolites), and (2) up to 9,231 volunteers for Biocrates LC-MS analysis (549 metabolites). Moreover, we updated the number of samples up to 4,599 volunteers, for NMR metabolome analysis of samples at repeat assessment survey. In addition, we updated the information of each metabolite (chemical structure and "common name") .
Metagenome
We released the relative abundances of microbial taxonomy identified by 16S rDNA V3-V4 region amplicon sequencing in saliva and dental plaque obtained from 1,388 volunteers.
User Interface Changes
We redesigned the UI of jMorp website to make it easier to grasp the relationships between data distributed from the database. jMorp is a multi-omics database, and contains many kinds of data including genome sequence, genome variations, transcriptome, metabolome, etc. But one of weaknesses was the thin links between datasets in the database. In this update, for example, the genome variant (SNV/INDEL) page displays the GWAS analysis results in which the variant is detected as significant, allowing users to jump to different layers such as omics data.
